
记一次小型生产事故 | BeyondComper跨编码方式复制文件内容
前言
今天组长在做站内巡检的时候,发现header内有一条meta标签的content显示为乱码。
我们版本是由svn控制的,组长使用blame看见是我提交的文件,就丢给我。
虽然已经是2个月前的提交,但是我还是稍微有点印象。
那是一次从测试站到正式站的代码合并,使用了BeyondCompare(下文简称为BC)的文件夹对比功能,逐个文件进行对比合并。
发现
首先确认了测试站和正式站文件的内容是一样的,而测试站中头部文件的编码方式是UTF-8,而正式站中头部文件的编码方式是GB2312。这让我感到非常奇怪,因为不论是用BC文件拷贝还是IDE的文件创建,都不会出现非UTF-8编码的文件。
追溯查询了上一次提交所有文件的编码方式后发现,非UTF-8编码的文件还有很多。
测试
于是我打算造个环境测试一下,建了两个空文件夹test1、test2,test1中放入一个随意汉字内容的UTF-8编码test.html。
- 先使用BC的目录复制到右边功能,从test1复制到test2,经查test2/test.html的编码方式还是UTF-8。
- 清空test2/test.html的内容,并将编码方式改为ansi。
- 再使用BC的打开文件复制到右边功能,从test1/test.html复制到test2/test.html,汉字复制过去了。
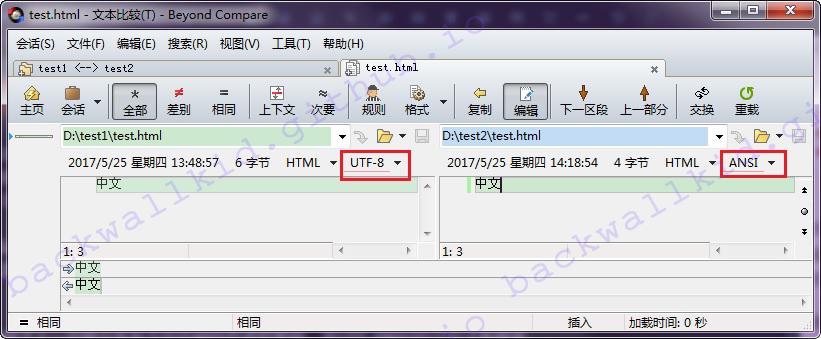
如红框显示,只是文字内容复制过去,编码方式却没有。
推测
于是我推测出2个月前的经过是这样的:
在进行文件夹内容合并的时候,我发现正式站文件夹内已经有了一个空的头部文件html。
于是我在使用BC进行内容合并的时候不是直接拷贝文件,而是点进文件内复制了内容,却没有看到BC右上角提示的不同的文件编码方式。导致一个GB2312的汉字头部文件进了UTF-8编码的网站。
总结
去追究谁造的GB2312空头部文件已经没有意义了,组长真正的责难点在于我在复制文字的过程中没有检查编码方式不同,还把这个文件投产了。
通过这个生产事故,再次敲响警钟,始终要记得检查文件编码方式。
